Python 并发编程之多线程由浅入深
在python中我们想要了解并发编程,就要知道在并发编程这里我们包含了两部分一部分是多线程,一部分是多进程。那么你具体能知道它们的区别吗?一起来看看!
线程与进程的区别
一个进程是操作系统中运行的一个任务
当前的操作系统基本都支持多进程的并发操作。
进程拥有独立的CPU、内存等资源。
一个线程是一个进程中运行的一个任务
一个进程中同样可以并发多个任务。
线程之间共享进程的CPU、内存等资源。
看了上述描述,可能感觉还是蒙蒙的,总结来说: 多个进程中的内存 cpu等资源是独立的不分享的。线程是进程中的一个任务,线程之间的CPU、内存等资源都是共享的。
代码解释多线程入门
1
2
3
4
5
6
7
8
|
def task():
for j in range(10):
print(j)
task()
task()
|
那么我们上面的代码可以看出很简单,只是简单的创建了一个函数遍历了10,然后被调用2次, 输出结果为两次0-9,可以看出顺序和你调用输出是一致的,那么我想使用多线程改造这个函数怎么来呢?下面继续
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| from threading import Thread
def task(numbers):
for j in range(numbers):
print(j)
thread1 = Thread(target=task,args=(10,))
thread2 = Thread(target=task,args=(10,))
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print("主线程结束了")
|
此时可以看到我们导入了一个包就是从threading里面导入了Thread,这个就是python处理多线程的函数,其中target为目标函数此时传递我们要执行的函数,记住千万不能加(),join方法就是等待改线程结束,然后主线程才可以往下继续执行。args就是我们传入的参数的意思,这里要求的格式必须是元组。要执行对应的多线程直接调用start即可。
输出结果如下:
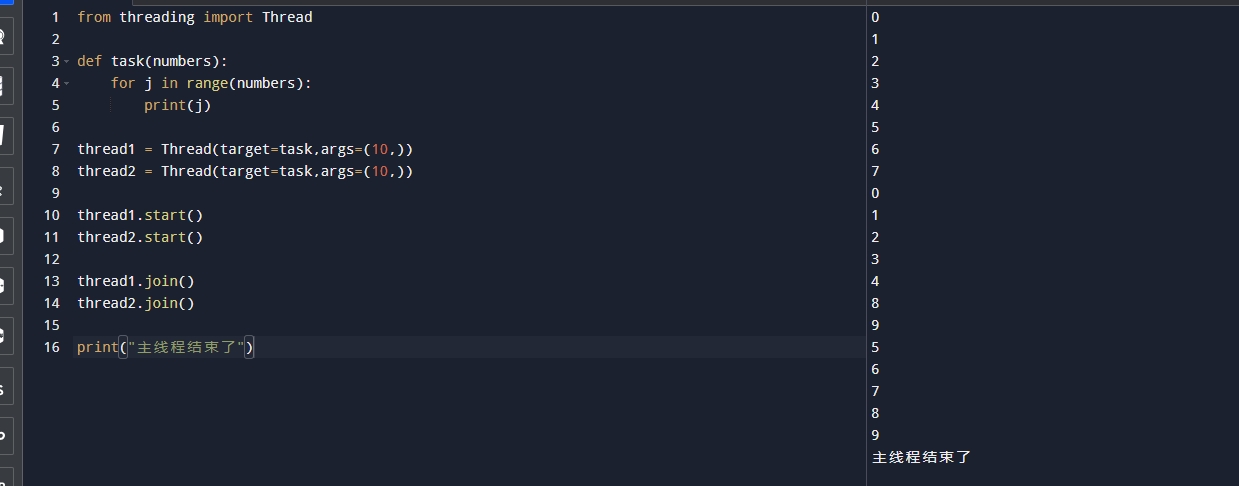
可以看到一个奇怪的现象就是这个输出结果有点顺序不对了,有的9和其他的数字混在后面了,是因为线程是并行的所以有时候你无法控制哪一个线程先优先输出数据。
代码解释线程进阶
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| from threading import Thread
import time
class ThreadTask(Thread):
def __init__(self, name, numbers):
super().__init__()
self.setName(name)
self.numbers = numbers
def run(self):
for n in range(self.numbers):
print(f"{self.getName()} - {n}")
time.sleep(0.01)
mythread1=ThreadTask("A", 10)
mythread2=ThreadTask("B", 10)
mythread1.start()
mythread2.start()
|
代码解释:从上述代码我们就可以看出我们这次写的是类而不是函数,那么我们是继承了Thread,然后在定义的__init__方法中我们初始化了父类的方法,其中setName() 用来展示线程的名字,这个是父类中已经有的函数。那么我们下面依旧是一个遍历和我们最初的是一样的。可以看到运行的结果如下:
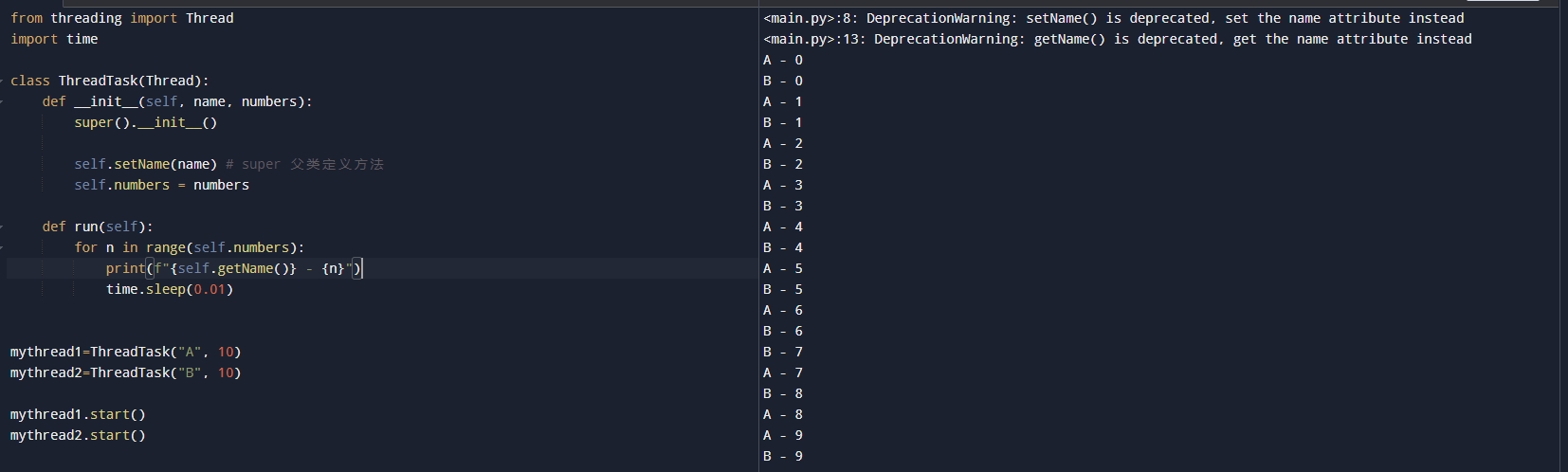
守护线程是什么?
下面我们来介绍一下什么是守护线程,守护线程就是主线程结束了守护线程也会结束,非守护线程就是主线程必须等非守护线程结束主线程才会结束。
代码解释守护线程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| from threading import Thread
import time
class ThreadTask(Thread):
def __init__(self, name, numbers):
super().__init__()
self.setName(name)
self.setDaemon(True)
self.numbers = numbers
def run(self):
for n in range(self.numbers):
print(f"{self.getName()} - {n}")
time.sleep(0.01)
mythread1=ThreadTask("A", 10)
mythread2=ThreadTask("B", 10)
mythread1.start()
mythread2.start()
|
代码解释:如果你是函数执行那么你在thread(task=mytask,daemon=True)的时候直接传入新的参数daemon=True即可,就可以实现守护线程,如果是通过继承Thread的方式,那么在初始化的时候调用父类方法setDaemon(True)即可实现守护线程。那么运行程序可以看到如下:

可以看到此时只是各自输出了0就结束了,因为此时主线程已经执行完毕,守护线程也会执行结束。
那么我们也可以增加join等待就可以实现等待守护线程执行完毕后在结束,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| from threading import Thread
import time
class ThreadTask(Thread):
def __init__(self, name, numbers):
super().__init__()
self.setName(name)
self.setDaemon(True)
self.numbers = numbers
def run(self):
for n in range(self.numbers):
print(f"{self.getName()} - {n}")
time.sleep(0.01)
mythread1=ThreadTask("A", 10)
mythread2=ThreadTask("B", 10)
mythread1.start()
mythread2.start()
mythread1.join()
|
运行结果如下:
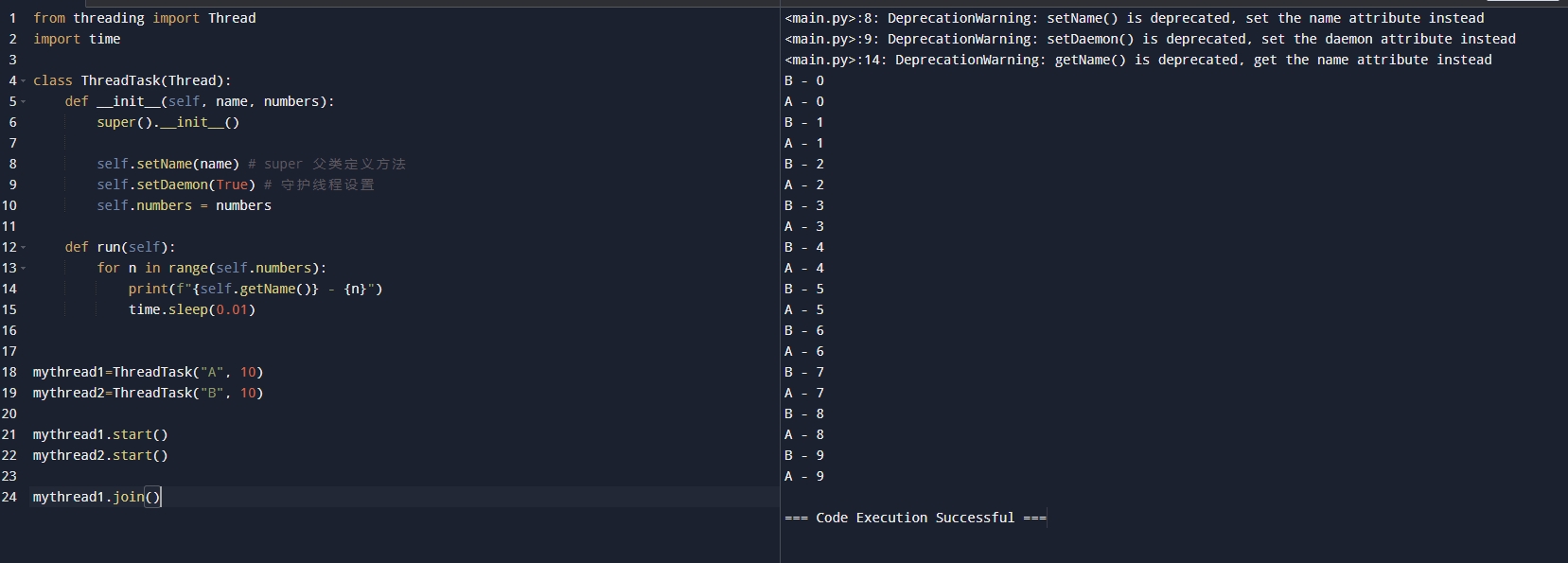
守护线程的应用场景
守护线程一般用在非关键性的线程,如日志、无关紧要的逻辑等都可以在主线程结束后也理解停止运行。
线程安全队列
从现在开始我们描述一个新的概念是队列,之所以在这里讲这个,是因为我们的线程是不安全的!因为我们的线程有可能发生多个线程的混乱。那么我们期望我们的是一个完整的有序的,就用到了我们的线程安全队列。
假如:我们有两个线程一个用来放,一个用来取,如果此时线程先运行了取后面才运行了放,那么就会发生问题,因为取不到,就是不安全的!
那么在python中的queue中的模块Queue就提供了线程安全队列的功能,我们可以一起来使用!
队列里面的一些方法
| 方法 |
解释 |
| queue.put(item,block=False) |
队列放入元素的时候如果满了则会抛出异常,改为True则会一直等待下去 |
| queue.put(item,timeout=3) |
队列放入元素满了则会等待3秒,超过3秒抛出异常 |
| queue.get(block=False) |
队列获取元素的时候如果为空则会抛出异常,改为Treu则会一直等待下去 |
| queue.get(timeout=3) |
队列获取元素空了则会等待3秒,超过3秒抛出异常 |
| queue.qsize() |
队列长度 |
| queue.empty() |
队列是否为空 |
| queue.full() |
队列是否已经放满了 |
队列代码生产者消费者
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| from threading import Thread
import time
from queue import Queue
class MessageProducer(Thread):
def __init__(self, name, numbers, queue):
super().__init__()
self.setName(name)
self.numbers=numbers
self.queue = queue
def run(self):
for n in range(self.numbers):
message = f"{self.getName()} - {n}"
self.queue.put(message, block=True)
class MessageConsumer(Thread):
def __init__(self, name, queue):
super().__init__()
self.setName(name)
self.setDaemon=True
self.queue = queue
def run(self):
while True:
message = self.queue.get(block=True)
print( f"{self.getName()} - {message}\n", end='')
queue = Queue(3)
threads = list()
threads.append(MessageProducer("PA",10,queue))
threads.append(MessageProducer("PB",10,queue))
threads.append(MessageProducer("PC",10,queue))
threads.append(MessageConsumer("CA",queue))
threads.append(MessageConsumer("CB",queue))
for t in threads:
t.start()
|
代码解释:在上述代码中我们创建了一个生成消息的生产者,创建了一个消费消息的消费者,其中在生产者中,我们除了之前的代码我们新增了一个queue,也就是一个队列,此时我们也引入了Queue,那么我们在run方法中呢多了一个将消息放入到队列中,其中我们用到了put方法,这个在上面的方法介绍中也写到了。
然后我们在消费者这里也是声明了一个queue,然后我们声明了我们的线程是守护线程,之所以声明是守护线程因为我们要用while true的方式去数据,一旦主线程结束那么我们的线程也需要结束否则会死循环。这里我们也使用了get方法,在我们的上面也同样介绍了该方法,然后我们打印了消费者的线程名称以及生产者的线程名称和放入的数据!
那么我们后面声明了一个队列,队列的长度是3,我们写了一个列表将生产者写了3个线程,消费者写了2个进程,这样我们就可以看到两个消费者和生产者之前的争夺关系!运行结果如下:
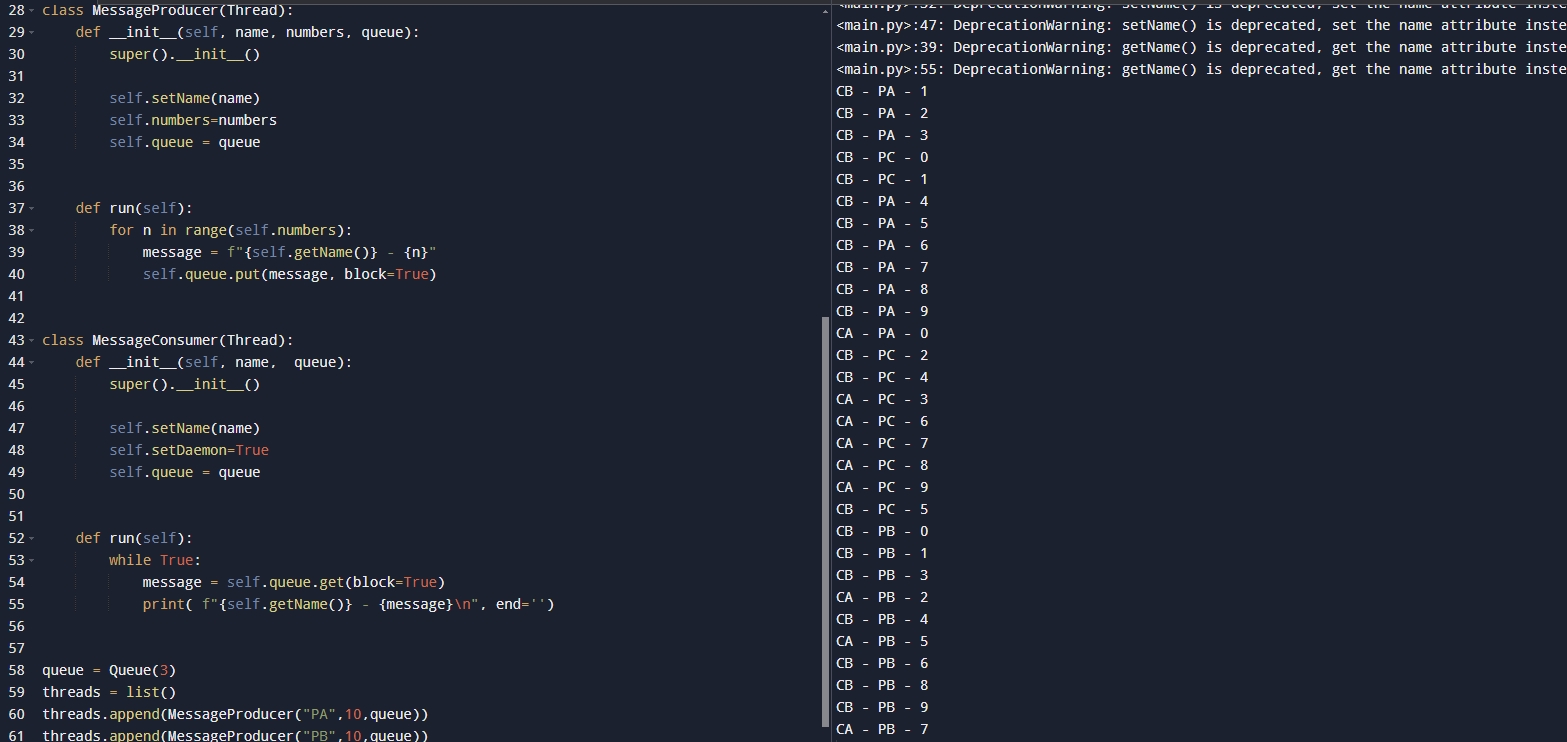
线程锁
首先我们来看什么事线程锁以及为何需要线程锁,当多个线程在同一时刻访问相同的数据时可能会产生数据丢失,覆盖,不完整等问题。那么线程锁就是用来解决这个问题的重要手段!
代码解释线程争夺
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| from threading import Thread
def task(name):
for i in range(3):
print(f"{name} -round {i}- stpe 1")
print(f"{name} -round {i}- stpe 2")
print(f"{name} -round {i}- stpe 3")
t1=Thread(target=task,args=("A",))
t2=Thread(target=task,args=("B",))
t3=Thread(target=task,args=("C",))
t1.start()
t2.start()
t3.start()
|
代码解释:上述代码中我们声明了一个task函数其中遍历3次打印传入的名字,这里我们声明了3个线程然后调用start运行,结果如下:
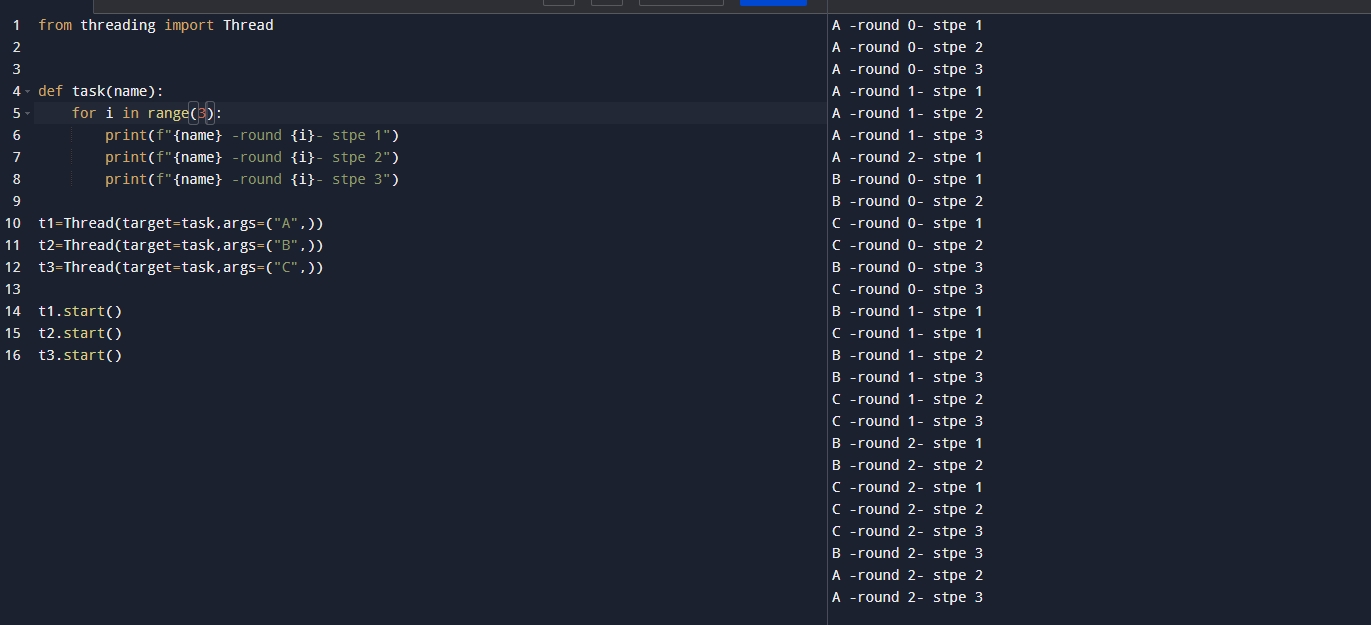
可以看出本应该是按顺序打印的但是我们还是发现了A B C的顺序不一致的情况,假如是一个需要按照顺序的写操作则会带来致命的麻烦!
代码解释加锁
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| from threading import Thread, Lock
lock = Lock()
def task(name):
global lock
for i in range(3):
lock.acquire()
print(f"{name} -round {i}- stpe 1")
print(f"{name} -round {i}- stpe 2")
print(f"{name} -round {i}- stpe 3")
lock.release()
t1=Thread(target=task,args=("A",))
t2=Thread(target=task,args=("B",))
t3=Thread(target=task,args=("C",))
t1.start()
t2.start()
t3.start()
|
代码解释:这里我们首先解释Lock(),也是在threading中给我们提供的方法,用来实现获取锁,使得线程可以按照首次运行时候的顺序执行,但是需要注意的是我们这里写了一个acuire() 就是上锁,release()就是释放锁,但是需要注意:当锁释放后,不会按照我们的顺序到第二个去拿锁,因为此时谁会拿到锁是随机的,是操作系统进行分配的,这里依旧是一个随机的顺序!执行结果如下:
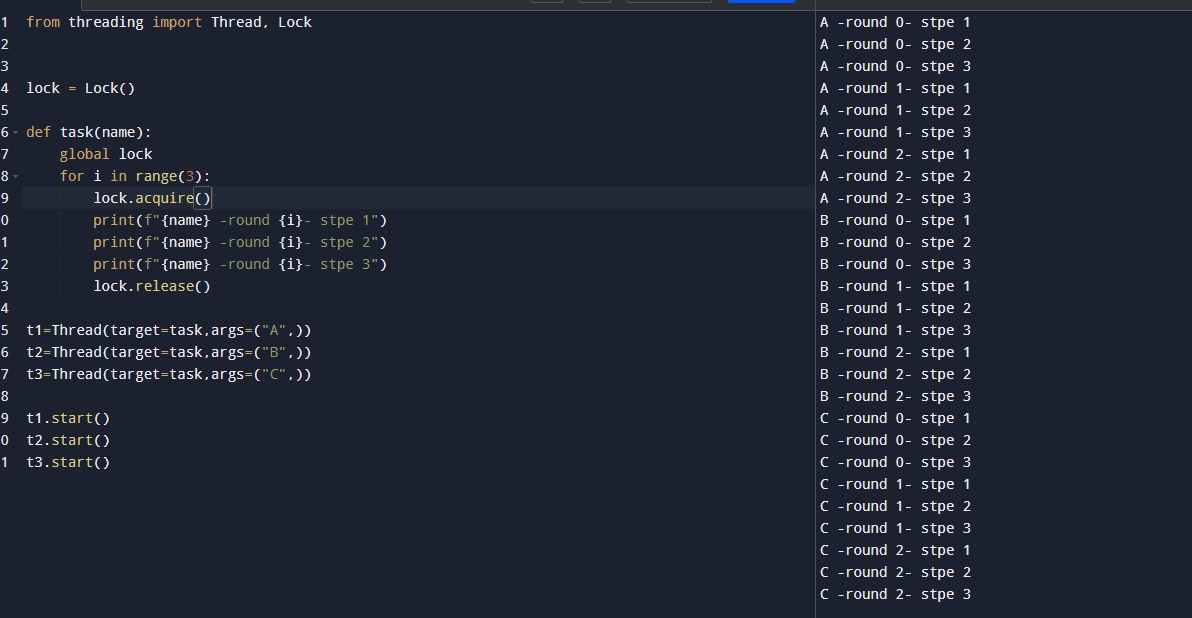
代码解释手动编写安全队列利用锁
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| from threading import Thread, Lock, Condition
from queue import Queue
class safeQueue:
def __init__(self, size):
self.__item_list = list()
self.size = size
sefl.__item_lock = Condition()
def put(self,item):
with self._item_lock:
while len(self.__item_list) >= self.size:
self.__item_lock.wait()
self.__item_list.insert(0, item)
self.__item_lock.notify_all()
def get(self, item):
with self._item_lock:
while len(self.__item_list) == 0:
self.__item_lock.wait()
result = self.__item_list.pop()
self.__item_lock.notify_all()
return result
|
代码解释:这里我们可以看到我们声明了一个类,这里在初始化的时候声明了一个list,一个size,一把锁注意这里的锁用的是Condtition,不是上面的Lock。这里的Condition()里面有这么几个方法:wait() 如果锁需要等待通知后才会运行, notify_all() 用于通知wait()这里是通知所有的锁,因为如果是notify是只会通知一把锁,也是随机的,这里通知所有的锁是为了避免通知到不是需要的锁。
那么我们这里依旧是写了一个队列的放入和取出的逻辑,其中在put逻辑中,我们首先是加了一把锁,因为我们进来的时候需要让其他的先等待,然后我们判断当前的队列的长度是否满了,如果满了就wait,此时在get中有一个notify_all的操作就是我们取出了就会通知所有锁可以醒来了,之所以这里使用的是while,是因为我们的锁可能醒来的不是对的,所以要每次都校验一遍!然后放入list中的第一个位置。
在get逻辑中我们也是先加了一把锁,然后校验list的长度是否为0,如果为0则会执行wait等待,然后我们在Put方法中依旧有一个notify_all的通知,就是我们放入一个元素就通知给get然后也是通知所有的锁,也是进行了while的校验,和上面put锁的机制是一样的!
在锁这里是支持上下文操作的,所以我们只需要执行 with self._item_lock:在结束的时候会自动执行释放锁的操作!
线程池
在了解线程池之前,我们可以来看一下在创建线程的时候我们要付出的代价有多大!
1.线程的创建和销毁相对比较昂贵
2.频繁的创建和销毁线程不利于高性能
线程池是一个可以便于管理和提高性能,也就是一个非常好的管理线程的工具!
代码解释创建线程池
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| import time
from concurrent.futures import ThreadPoolExecutor
def task(name):
print(f"{name} -step 1")
time.sleep(1)
print(f"{name} -step 2")
return f"{name} complete"
with ThreadPoolExecutor() as executor:
re1 = executor.submit(task, 'A')
re2 = executor.submit(task, 'B')
print(re1.result())
print(re2.result())
|
代码解释:首先我们引入了线程池 from concurrent.futures import ThreadPoolExecutor,然后我们创建了一个task函数,可以传递一个name作为打印信息,后面return 回去这个name,因为线程池是支持上下文管理器的,所以我们写了一个上下文管理器来创建线程池,submit()用来提交一个线程,result() 用来获取返回值,reuslt会等待有结果的时候才返回!结果如下
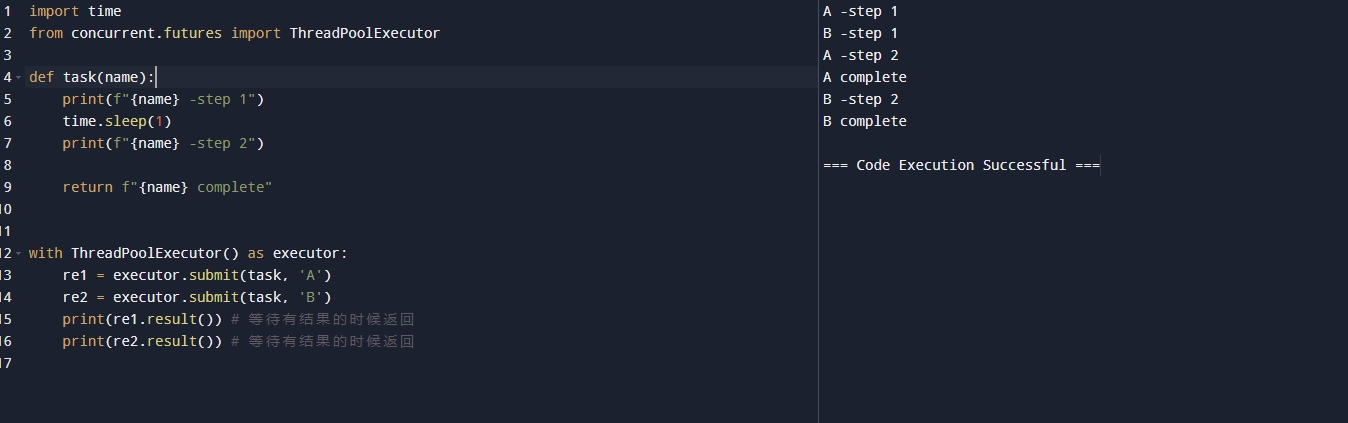
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| import time
from concurrent.futures import ThreadPoolExecutor
def task(name):
print(f"{name} -step 1")
time.sleep(1)
print(f"{name} -step 2")
return f"{name} complete"
with ThreadPoolExecutor() as executor:
results = executor.map(task, ['A','B','C'])
for i in results:
print(i)
|
代码解释:这里我们改造了使用map()提交,主要用于我们同一个函数,传递不同的值这样我们就可以很方便不需要每次的submit,只需要这样写就可以达到同样的效果。运行结果如下:
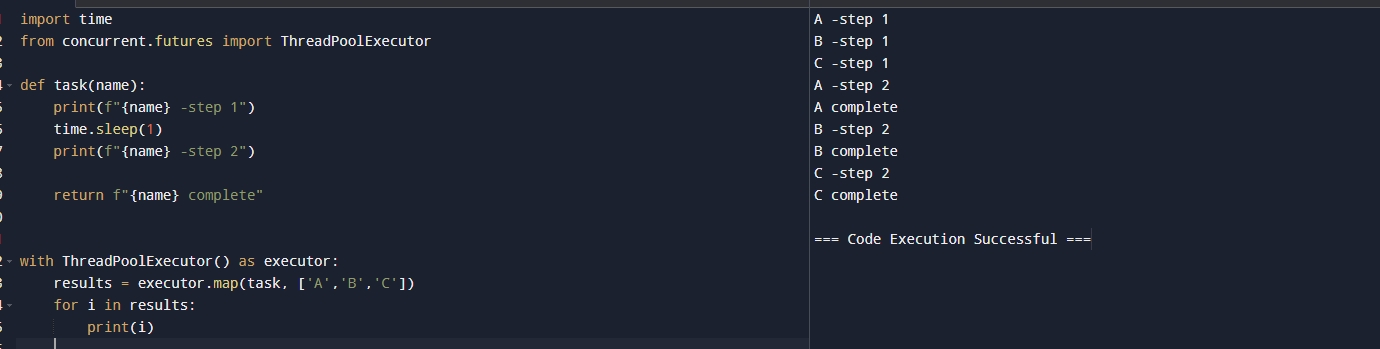
代码解释下载图片利用线程池
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| import time
from concurrent.futures import ThreadPoolExecutor
from urllib.request import urlopen, Request
import os
def download_img(url)
headers = {
"user-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36"
}
site_url = Reuqest(url, headers=headers)
with urlopen(site_url) as web_file:
img_data = web_file.read()
if not img_data:
raise Exception(f"Error: download error from {url} ")
file_name = os.path.basename(url)
with open(file_name, "wb") as file:
file.write(img_data)
return f"Download image successfully, {url}"
with ThreadPoolExecutor() as executor:
urls = {
"demourl",
"demourl",
"demourl"
}
results = executor.map(download_img, urls)
for res in results:
print(res)
|
代码解释:这里我们是写一个下载图片的案例,首先我们引入了urlopen, Request这里不再讲述相关库的介绍,感兴趣可以自行查询,然后我们也是做了对应的请求,然后存储到本地,这里urls 可以使用你们找到的图片网址,然后我们使用线程池来实现下载即可,这里和上述没啥区别,更多的是有了具象化的感觉。
总结
我们这次虽然文字众多,但是我们从线程和进程的区分到线程的每一步进阶,到队列,锁,线程池等完全覆盖所有线程相关的重要知识点,希望各位同学都可以把握这些重要的知识点,对我们的工作将会有很大的帮助!