ollama部署本地大模型
ollama部署本地大模型以及python调用
1.什么是ollama
Ollama 是一个开源的大语言模型(LLM)本地部署框架,旨在让用户能够像使用 Docker 一样,通过极简的命令行操作在个人电脑(macOS、Windows、Linux)上快速运行、管理和部署各种开源模型。
2. 安装ollama
访问网站:https://ollama.com/
然后根据你的平台选择不同的的方式,我的是windows,需要下载一个.exe的安装文件。
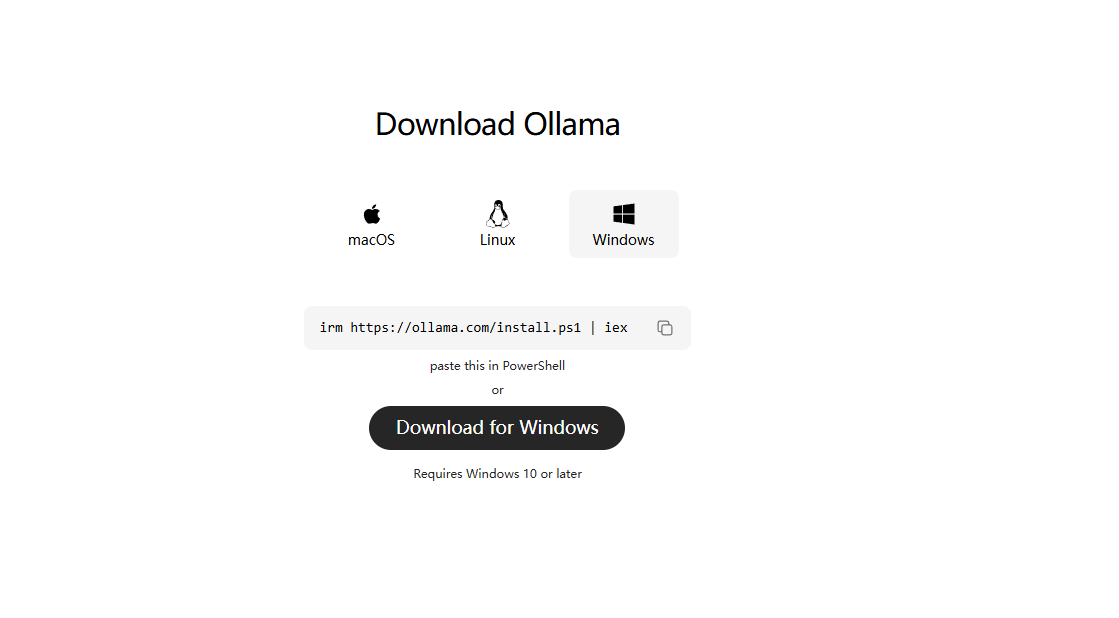
安装路径选择
ollama 在windows下无法选择安装的路径,直接就安装到了C盘,这是我们无法接受的!所以我们需要更改路径,那么具体如下:
1 | |
模型路径选择
虽然我们将安装路径选择了D盘,但是模型的下载路径依旧在C盘,具体路径是:C:\Users\<用户名>\.ollama。 这样就会有一个问题,那就是模型很大下载后依旧会占用C盘的空间,所以我们需要将其修改到D盘。
环境变量设置
PATH:
- 右键“此电脑” → “属性” → “高级系统设置” → “环境变量”
- 在“系统变量”或“用户变量”中找到 Path,编辑并替换旧路径为新路径(如 D:\AI\Ollama)
4.重启命令行或系统,验证是否生效:
ollama -v

此时你需要确认的是:
- 停止 Ollama 服务:
- 打开任务管理器 → 结束所有 ollama.exe 进程
- 或在 CMD 中运行:
taskkill /f /im ollama.exe
- 重启电脑
电脑重启完毕后,我们开始下载模型
模型下载
我们还是登录ollama 的官网 https://ollama.com/search
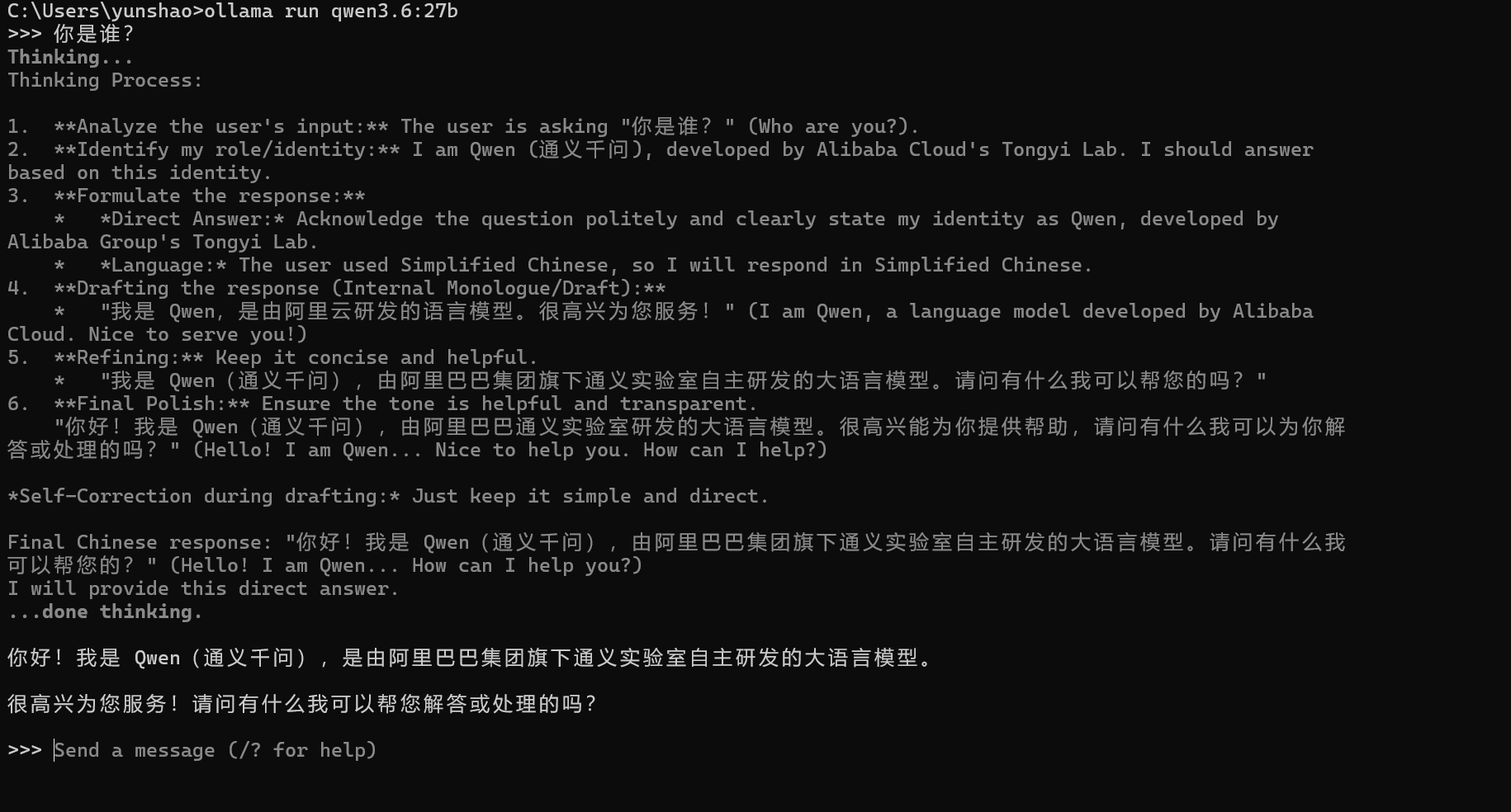
这里是下载模型的地方,我们可以选择适合自己电脑配置的模型,例如qwen3.6:27b
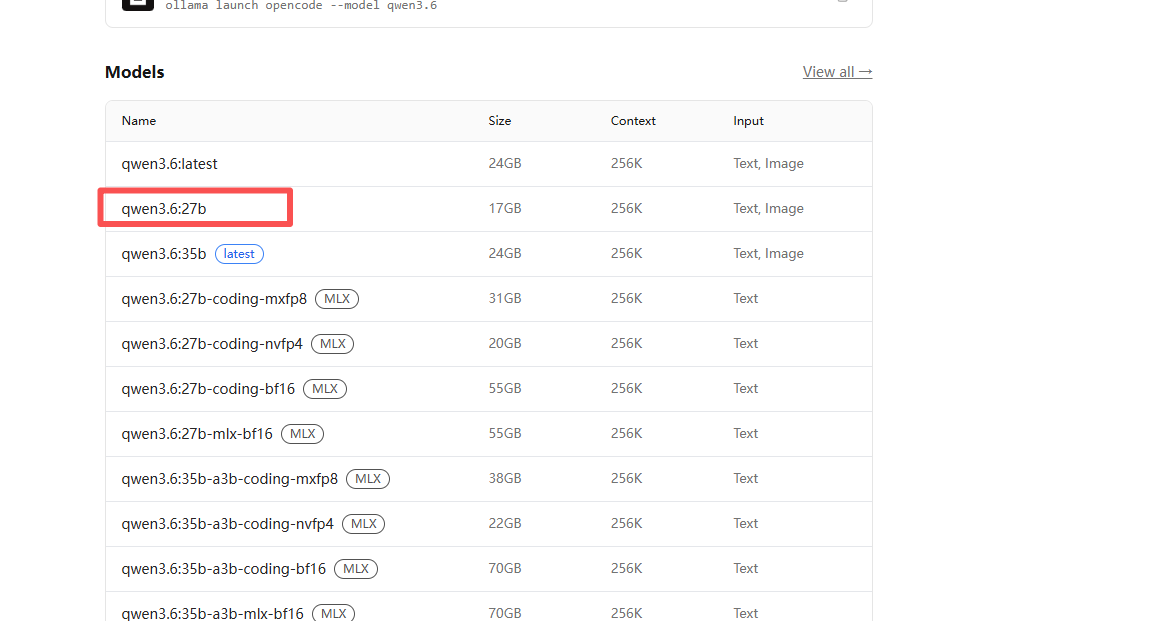
但是这个对于电脑要求性能很高,显卡的显存最好在16G以上,我本地的是8G的显存,在调用的时候会在6分左右给到我答案(通过python调用),通过ollama 命令行,会展示思考的过程!
具体cmd下载命令:
ollama run qwen3.6
你也可以选择其他的,那么就在模型的下方有下载的命令
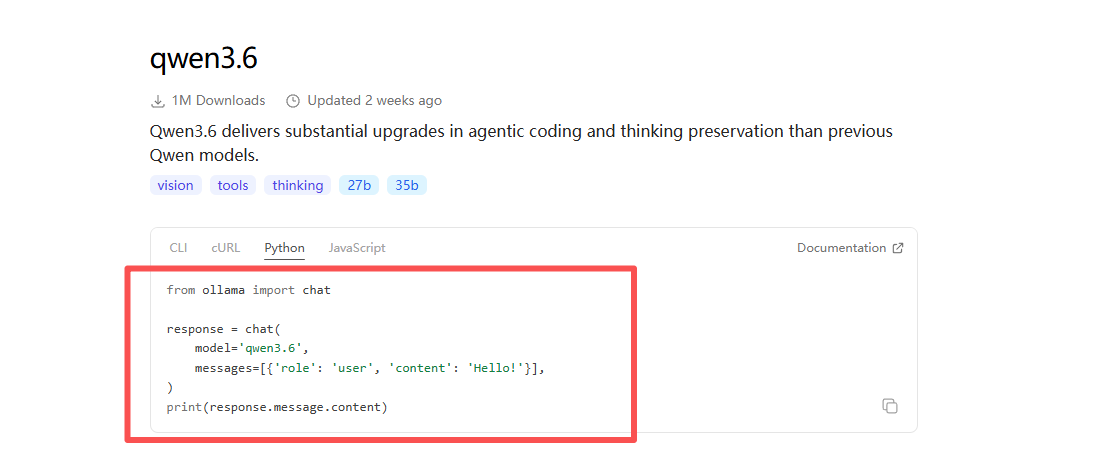
执行完毕,就等待下载模型就行,此时会在你定义的模型下载文件夹中出现两个文件夹

此时就下载完毕了!
注意
我本地在下载模型的时候不知道为什么仍然会下在到C盘默认路径下,那么如果你和我的情况一样,则不要担心,只需要将C:\Users\<用户名>\.ollama\models 文件夹下的 blobs, mainfetsts 文件下的对应内容迁移到D盘就行,直接剪切!
文件夹都是相同的!
模型查看
下载模型完毕后,执行下面的命令可以看到你的模型有那些
1 | |

ollama 基础命令
核心终端命令
这些命令在 CMD、PowerShell 或终端中直接运行:
- 模型运行与下载
- ollama run <模型名>:运行模型。如果本地没有该模型,会自动从库中拉取。
- ollama pull <模型名>:仅下载/更新模型,不直接运行。
- 模型管理
- ollama list:列出所有已下载的模型及其大小、ID。
- ollama ps:查看当前正在内存中运行的模型。
- ollama rm <模型名>:删除指定的本地模型以释放空间。
- ollama cp <原模型> <新名称>:复制并重命名模型。
- 信息查询
- ollama show <模型名>:显示模型的详细信息(如参数量、量化格式、Modelfile 结构)。
- ollama –version:查看当前 Ollama 的版本号。 [1, 2, 3, 4, 5, 6, 7]
交互会话指令当你运行
ollama serve:手动启动 Ollama 服务端(通常软件会自动在后台运行,但在 Linux 上调试时常用)。
ollama create <新名> -f <Modelfile路径>:通过自定义的 Modelfile 配置文件创建一个新模型(比如给模型预设特定的身份)。 [1, 12, 13, 14]
💡 小技巧:
如果你需要输入多行文字(如粘贴一段长代码),在交互模式下可以使用
“””(三个双引号)包围你的内容,完成后再输入
“”” 结束并发送。 [8, 15]
模型调用
命令行调用
首先我们执行 ollama server 将服务开启(开启了就不需要了)
然后执行唤起大模型命令 ollama run qwen3.6,z 这个命令会先检查本地是否有这个模型,如果没有会先下载然后打开,有的话就会直接运行!
打开成功后!如下:
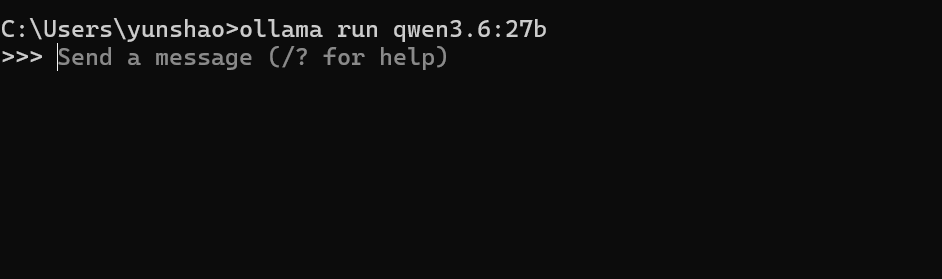
我们尝试问一些内容:
python 基础代码调用
安装完毕模型后,我们也可以通过脚本的方式调用,需要安装一个python的三方包 ollama
1 | |
然后可以编写脚本:
1 | |
这里我们增加一个时间计时器,因为这个模型参数比较大,我的是50570(8G)+32G的内存,运行起来还是比较吃力的!

可以看到通过python 调用的时间是6分钟多,当然我们可以选择更小的模型这样的会更快!
总结
部署本地大模型对于不方便上云的业务很好,但是越好的模型对于硬件要求也越高!大家可以选择适合自己的模型!